
2026. 4. 2. 08:45ㆍOpen Seminar/Reinforcement Learning
서론: 강화 학습으로 루빅스 큐브를 풀 수 있을까?
이번 세미나에서 저는 강화 학습(Reinforcement Learning)을 주제로 첫 번째 스터디 발표를 진행했습니다. 단순히 이론만 다루기보다는 흥미로운 응용 사례를 함께 살펴보고 싶었고, 그래서 선택한 논문이 바로 "Solving the Rubik's Cube with Deep Reinforcement Learning and Search" (Nature Machine Intelligence)입니다.
이 논문은 강화 학습(Value Iteration), 딥 뉴럴 네트워크(DNN), 그리고 A* 탐색 알고리즘을 결합하여 루빅스 큐브를 풀어내는 방법을 제안합니다. 이번 글에서는 발표 자료를 바탕으로 논문의 핵심 아이디어와 그 배경이 되는 강화 학습 이론을 정리해보겠습니다.

Solving the Rubik's cube with deep reinforcement learning and search 논문
1. 논문 소개
이번에 다룬 논문은 Forest Agostinelli 등이 Nature Machine Intelligence에 발표한 논문입니다. 논문의 핵심을 한 줄로 요약하면 다음과 같습니다.
방법: Reinforcement Learning (Value Iteration) + Deep Neural Network (파라미터 조정을 통한 함수 근사) + Search (A* Search)

논문에서 사용한 세 가지 핵심 방법론: Value Iteration, DNN, A* Search
즉, 강화 학습으로 휴리스틱 함수를 학습하고, 이를 A* 탐색에 활용하여 루빅스 큐브의 해법을 찾아내는 구조입니다.
2. 루빅스 큐브 이해하기
2.1 기본 구조
루빅스 큐브는 1974년 헝가리 건축가 에르뇌 루빅(Ernő Rubik)이 발명한 3D 회전 퍼즐입니다. 3×3×3 기본형 구조로, 각 면을 하나의 색으로 맞추는 것이 목표입니다.
큐브를 구성하는 조각(Cubelet)은 세 종류로 나뉩니다:
- Centre Cubelets: 스티커 1개 (각 면의 중심)
- Edge Cubelets: 스티커 2개 (모서리)
- Corner Cubelets: 스티커 3개 (꼭짓점)
총 26개의 큐브렛과 54개의 스티커로 구성되며, 6가지 색상을 가집니다. DNN의 입력으로 사용하기 위해 One-hot Encoding을 적용하면, $6 \times 54 = 324$차원 벡터로 큐브의 상태를 표현할 수 있습니다.

큐브렛 구성과 One-hot Encoding을 통한 324차원 벡터 표현
2.2 강화 학습 관점에서의 특징
루빅스 큐브가 강화 학습 문제로서 가지는 독특한 특징이 있습니다:
- 극도로 큰 상태 공간(Exceptionally large state space): 약 $4.3 \times 10^{19}$개의 서로 다른 상태가 존재합니다.
- 단 하나의 목표 상태(Only one goal state): 모든 면이 맞춰진 상태 하나만이 목표입니다.
- 무작위 시작(Sequence of random moves): 무작위로 섞인 상태에서 출발합니다.

$4.3 \times 10^{19}$개의 상태 공간, 단 하나의 목표, 무작위 시작이라는 세 가지 도전 과제
상태 공간이 이렇게 방대하기 때문에 단순한 탐색으로는 해결이 불가능하고, 효율적인 탐색을 유도할 휴리스틱이 필수적입니다.
3. 논문의 핵심 아이디어
3.1 전체 접근 방식
논문의 핵심 아이디어를 정리하면 다음과 같습니다:
- 루빅스 큐브를 상태 전이 구조를 탐색하는 문제로 접근합니다.
- 상태 공간은 크지만, 목표까지 남은 이동 횟수를 예측하는 휴리스틱 정보가 있다면 A* 탐색을 효과적으로 사용할 수 있습니다.
- 이 휴리스틱 정보는 Value Iteration + DNN을 결합하여 학습합니다.
- 학습된 휴리스틱 함수를 A* 탐색에 사용하여 거대한 상태 공간에서도 효율적으로 해답을 찾습니다.
3.2 학습 데이터 생성
학습 데이터를 만드는 방법이 매우 영리합니다. 목표(Goal) 상태에서 출발하여 무작위로 $K$번 섞어서 학습용 상태를 생성합니다. 이렇게 하면 $K$라는 정보, 즉 목표까지의 거리가 자연스럽게 주어지기 때문에, 네트워크가 상태와 목표까지의 거리 사이의 관계를 학습하기 훨씬 수월해집니다.
결과적으로 학습된 네트워크는 임의의 상태가 주어졌을 때, 목표 상태까지 도달하는 데 필요한 이동 횟수를 근사적으로 예측할 수 있게 됩니다.
4. Preliminary: A* Search
논문의 방법론을 이해하려면 A* 탐색 알고리즘에 대한 이해가 필요합니다.
4.1 A* Search란?
A* Search는 다익스트라(Dijkstra) 알고리즘의 변형으로, 시작 노드에서 목표 노드까지의 최적 경로를 찾는 알고리즘입니다. 핵심은 각 노드에서 목표 노드까지의 거리에 대한 추가 정보, 즉 휴리스틱(Heuristic)을 활용한다는 점입니다.
적절한 휴리스틱 함수 $h(v)$는 현재 정점 $v$에서 목표 정점 $t$까지의 거리를 추정하며, 다음과 같은 일관성(Consistency) 조건을 만족해야 합니다:
$$h(v) \leq c(v, v') + h(v')$$여기서 $c(v, v')$는 정점 $v$에서 $v'$까지의 실제 비용입니다.
4.2 휴리스틱의 효과
발표에서 그래프 예시를 통해 휴리스틱의 효과를 시각적으로 보여드렸습니다.
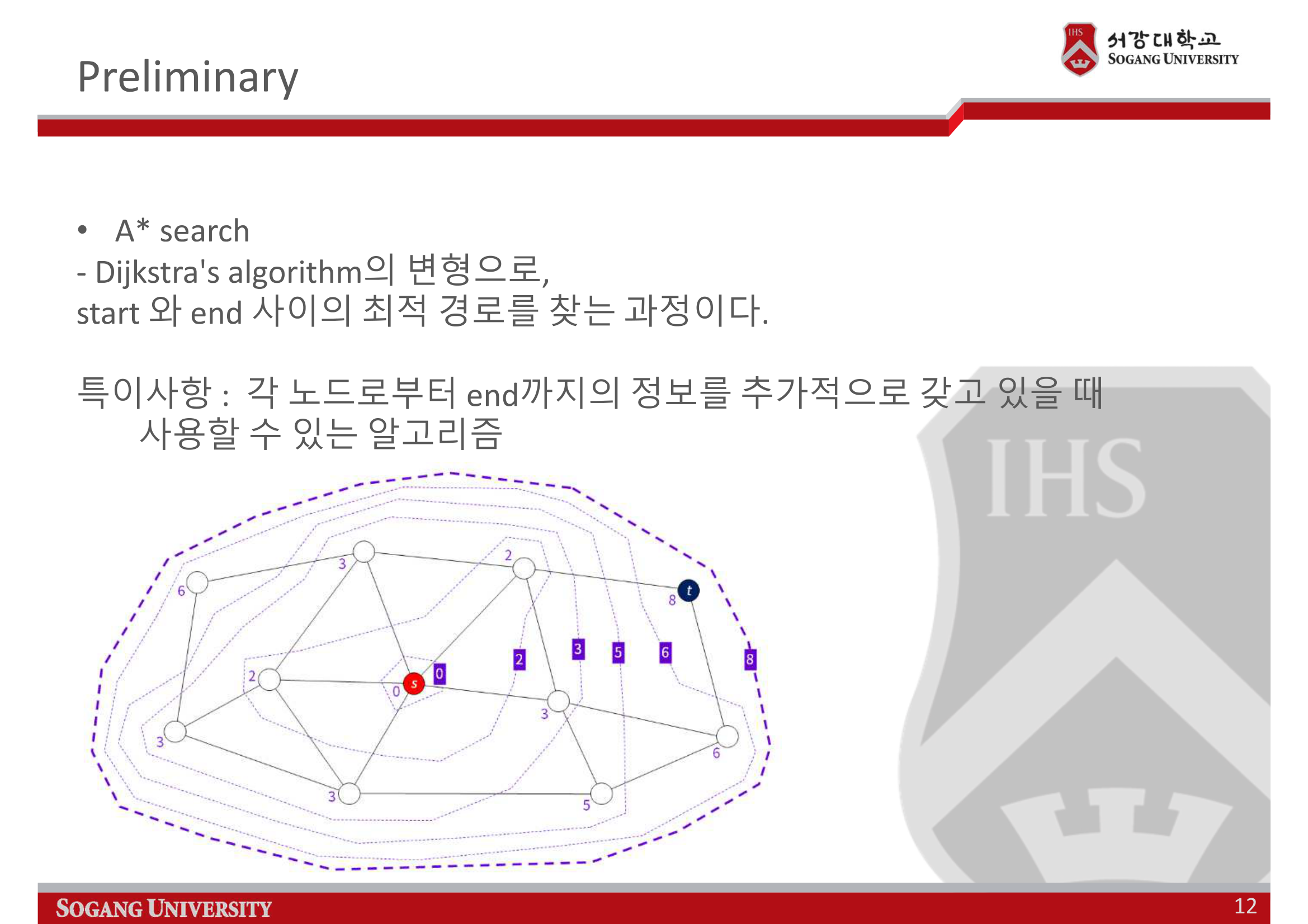
휴리스틱 없이 탐색하면 시작 노드에서 모든 방향으로 균일하게 확장됩니다. 보라색 숫자는 시작 노드로부터의 누적 비용 $g(n)$입니다.

휴리스틱을 사용하면 탐색이 목표 방향으로 집중됩니다. 주황색 숫자는 $f(n) = g(n) + h(n)$ 값으로, A*는 이 값이 작은 노드부터 확장합니다.
다익스트라 알고리즘은 모든 방향으로 균일하게 탐색을 확장하지만, A*는 휴리스틱 정보를 활용하여 목표 방향으로 탐색을 집중시킵니다. 이것이 바로 거대한 상태 공간에서도 효율적으로 해답을 찾을 수 있는 핵심 원리입니다.
5. Preliminary: Value Iteration
5.1 Value Iteration이란?
Value Iteration은 MDP(Markov Decision Process)를 해결하기 위한 동적 계획법(Dynamic Programming)의 한 방법입니다. MDP를 해결한다는 것은 최적의 정책(Optimal Policy) $\pi^*$를 찾는 것을 의미합니다.
Value Iteration은 벨만 최적 방정식(Bellman Optimality Equation)을 기반으로 합니다:
$$v^*(s) = \max_a \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma v^*(s') \right]$$5.2 구체적인 예시
발표에서는 로봇 자동차 예시를 통해 Value Iteration의 동작 과정을 설명했습니다.

로봇 자동차 예시: 상태(cool, warm, overheated), 행동(slow, fast), 보상을 기반으로 가치 함수를 반복 갱신하는 과정
- 상태(States): cool, warm, overheated
- 행동(Actions): slow, fast
- 보상(Rewards): slow → 1, fast → 2 (overheated 시 -10)
업데이트 규칙은 다음과 같습니다 ($\gamma = 1$로 가정):
$$V_{k+1}(s) = \max_a \sum p(s', r \mid s, a) \left[ r + \gamma V_k(s') \right]$$이 과정을 수렴할 때까지 반복하면 최적 가치 함수 $V^*$를 얻을 수 있습니다.
6. 논문에서의 강화 학습 이론
6.1 가치 함수 정의
강화 학습의 핵심 개념인 가치 함수를 정리합니다.
상태 가치 함수(State-value function):
$$v_\pi(s) = \mathbb{E}_\pi[G_t \mid S_t = s] = \mathbb{E}_\pi\left[\sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \mid S_t = s\right]$$상태 $s$에서 시작하여 정책 $\pi$를 따랐을 때 얻게 되는 총 보상의 기댓값입니다.
행동 가치 함수(Action-value function):
$$q_\pi(s, a) = \mathbb{E}_\pi[G_t \mid S_t = s, A_t = a] = \mathbb{E}_\pi\left[\sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \mid S_t = s, A_t = a\right]$$상태 $s$에서 행동 $a$를 취한 후, 정책 $\pi$를 따랐을 때 얻게 되는 총 보상의 기댓값입니다.
6.2 가치 함수를 아는 것의 의미
$V_\pi$를 안다는 것은 곧:
- 특정 상태의 좋고 나쁨을 평가할 수 있고,
- 여러 정책들의 가치 함수를 비교하여 가장 좋은 정책을 선택할 수 있다는 의미입니다.
6.3 최적 정책과 벨만 최적 방정식
강화 학습의 궁극적 목표는 장기적으로 가장 많은 보상을 얻는 정책, 즉 최적 정책 $\pi^*$를 찾는 것입니다.
최적 가치 함수:
$$v^*(s) = \max_\pi v_\pi(s)$$ $$q^*(s, a) = \max_\pi q_\pi(s, a)$$벨만 최적 방정식의 핵심 아이디어는 다음과 같습니다:
최적 정책을 따를 때 어떤 상태의 가치는, 그 상태에서 할 수 있는 최선의 행동을 했을 때 얻게 될 기대 보상과 같다.
이를 수식으로 유도하면:
$$v^*(s) = \max_a q^*(s, a) = \max_a \mathbb{E}\left[R_{t+1} + \gamma v^*(S_{t+1}) \mid S_t = s, A_t = a\right]$$ $$= \max_a \sum_{s', r} p(s', r \mid s, a) \left[ r + \gamma v^*(s') \right]$$한 문장으로 요약하면, "상태 $s$에서 시작하여 최적의 행동을 계속 취했을 때 받을 수 있는 최대 가치"입니다.
6.4 Value Iteration 알고리즘 정리
Value Iteration은 가치 함수 $V_k(s)$를 반복적으로 갱신하여 최적 가치 함수 $V^*(s)$에 수렴시키는 알고리즘입니다. 구체적인 단계는 다음과 같습니다:
- 초기화: $V_0(s)$를 임의의 값(예: 0)으로 설정
- 반복 갱신: 모든 상태 $s$에 대해, 각 행동 $a$를 취했을 때의 기대 가치를 계산하고 최댓값으로 업데이트 $$V_{k+1}(s) = \max_a \sum p(s', r \mid s, a) \left[ r + \gamma V_k(s') \right]$$
- 수렴까지 반복: $k$를 증가시키며 2번 과정을 반복하면 $V_k$는 점점 더 정확한 $V^*$로 수렴
7. 전체 방법론 요약
발표에서 손그림 다이어그램을 통해 논문의 전체 파이프라인을 정리했습니다.

A* 탐색의 각 상태에서 Value Iteration + DNN을 통해 목표까지의 남은 횟수(휴리스틱)를 학습하는 구조

전체 파이프라인 최종 요약: 목표 상태에서 k번 섞어 학습 데이터를 생성하고, Value Iteration + DNN으로 휴리스틱을 학습한 뒤, A* 탐색에 활용
전체 흐름을 다시 정리하면:
- 학습 데이터 생성: 목표 상태에서 $k$번 무작위로 섞어 다양한 상태를 만듭니다.
- 휴리스틱 학습: Value Iteration의 원리를 기반으로, DNN이 각 상태에서 목표까지의 남은 이동 횟수를 예측하도록 학습합니다.
- A* 탐색: 학습된 DNN이 출력하는 휴리스틱 값을 A* 탐색 알고리즘에 활용하여, $4.3 \times 10^{19}$개의 상태 공간에서도 효율적으로 최적 경로를 찾아냅니다.
마무리
이번 세미나에서는 강화 학습의 기본 개념(가치 함수, 벨만 최적 방정식, Value Iteration)부터 시작하여, 이를 A* 탐색과 DNN에 결합하여 루빅스 큐브를 풀어내는 논문의 방법론까지 살펴보았습니다.
특히 인상 깊었던 점은 다음과 같습니다:
- 학습 데이터 생성의 영리함: 목표 상태에서 역으로 섞어나가면서 자연스럽게 "거리" 레이블을 얻는 방식
- 세 가지 기법의 유기적 결합: Value Iteration으로 이론적 기반을 마련하고, DNN으로 함수를 근사하며, A* Search로 실제 탐색을 수행하는 구조
- 거대한 상태 공간에서의 효율성: 좋은 휴리스틱이 있으면 $10^{19}$ 규모의 공간에서도 해답을 찾을 수 있다는 점
다음 스터디에서는 강화학습의 일반적인 내용들을 풀어서 공유해보고자 합니다.
읽어주셔서 감사합니다.

* 이 글은 제가 만든 발표 자료 기반으로 AI를 사용하여 작성한 글 입니다. 발표자료는 아래 원본을 참고해주세요.
